

“It’s just data” says jokingly the president of a hotel-data analysis and industry leading software company. What value would his “data” hold for you? Probably not much since you don’t need it! I have found in time that one’s data becomes increasingly valuable in proportion to its meaningful association to other peoples’ data. We are talking about a “relation” between data sets. In 1969, Edgar Fr. Codd invented a database model which would organize digitized data into what would later be known as a “relational database.” Obviously, as its name indicates, a “relational DB” would hold relationships between data. This DB model would be different than a hierarchical database or network database.
WHAT IS A DATABASE?
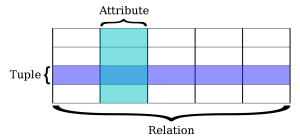
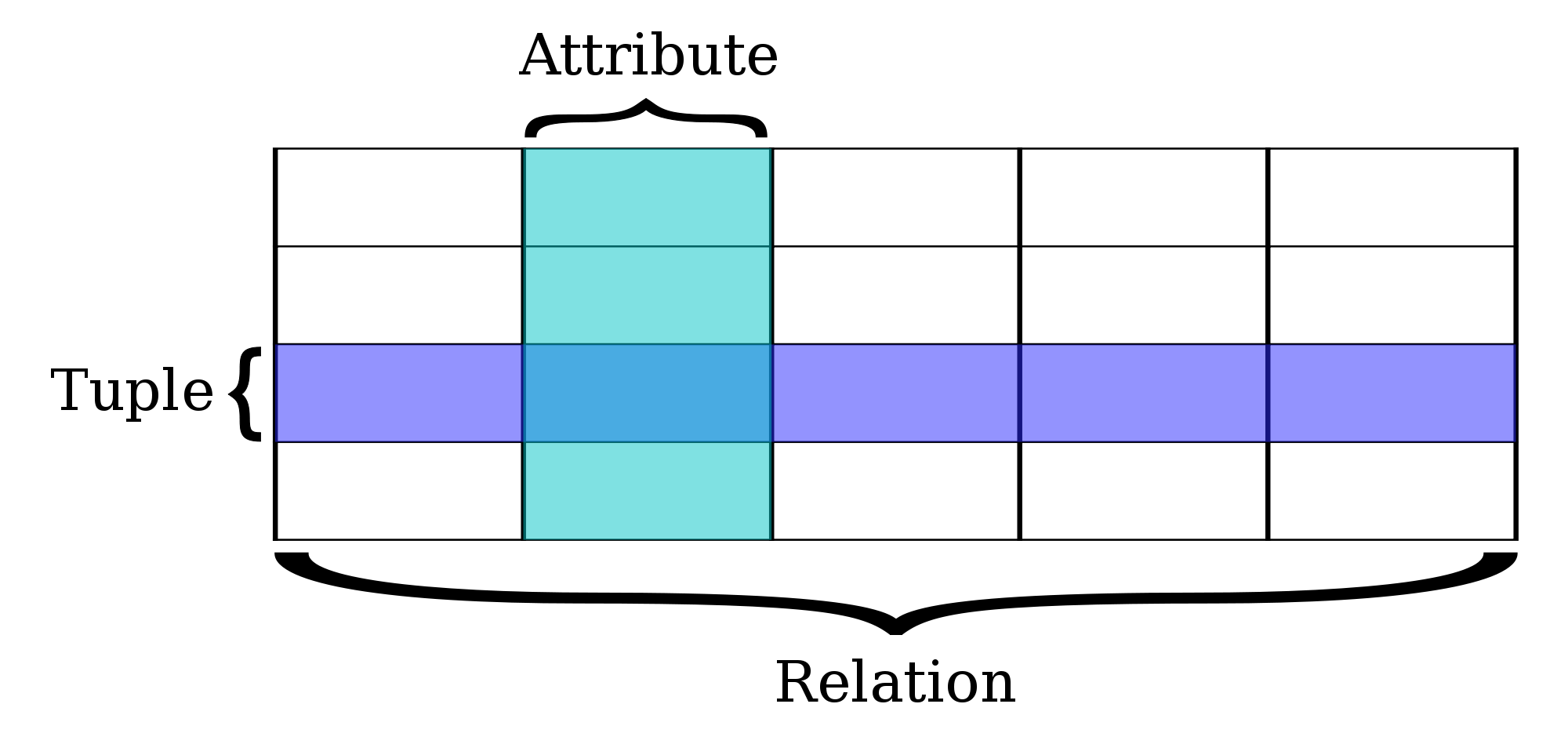
Well, a database is “data” organized as “entities;” digitized data stored on disk as “data entities.” These “data entities” are further organized into “sets” which we can be viewed as “tables.” In the context of a “Relational Database,” we are going to refer to these “sets” or “Tables” as “relations.” Each “relation” has attributes. A customer could have many attributes such as “Name,” “Tax-ID,” “Address,” “Number of employees,” etc. Each of these attributes is graphically represented in a table as a “Column.” Ultimately, one can see that these attributes define the “relation.” A “relation” can have many instances though and theseinstances are represented as rows (or tuples.)
|
|
 |
{kind=link}
Now, I think a “Relational Database” Model offers an amazing growth potential for businesses and individuals alike.
WHY?
- In Brief, the model more effectively reflects human footprints which originate from ever developing meaningful connections that will both forever exist (regardless of what the economy does) and be subject to further analysis.
Humor me for a second:
Despite what you might hear out there, MONEY does not make the world go around, “Relationships” do.
- Everything is designed to be connected!
- Everything exists in relationship.
- Nothing exists on its own.
- We, you and I, exists in connection with others.
Let’s start with the universe. Guess what? It exists in relationships:
{kind=link}

While it is connected atomically, moons orbit around planets. Planets orbit around stars. Stars orbit within galaxies and galaxies move around in the universe.
 A “Relation” could not exists by itself, right? For a “relation” to exist, you would need at least “two.”
A “Relation” could not exists by itself, right? For a “relation” to exist, you would need at least “two.”
Data by itself is meaningless. But “Relational Data” speaks to what we already know. Your Data is proportionally valuable to number of connections to other people’s data.
How do we manage all this relational data?
We need two things: A schema or definition of how “Relational Data” could be stored on a computer disk and a language to manipulate the data.
A number of “database management systems” has been created to manage “Relational Data.” They’re called relational database management system (RDBMS).
According to research company Gartner, the five leading commercial relational database vendors by revenue in 2011 were Oracle (48.8%), IBM (20.2%), Microsoft (17.0%), SAP including Sybase (4.6%), and Teradata (3.7%)
A “Relational data model” would define how we store this data; a “Relational data model” would have the following characteristics:
- Attributes in a table contain only one definition (type) and value. For example, if the attribute is labeled as Date, you would not enter a dollar amount, shirt size, or model number in that column, only dates.
- Table or relations are unique; rows or tuples are unique; attribute names are unique. There is no need to repeat the same thing!
- Tuples are not in order. Order should not define the set.
- A relation is to be dealt through its individual members but as a whole. A relation against another relation results in a relation.

SQL (pronounced “ess-que-el”) stands for Structured Query Language. SQL is used to communicate with a database. According to ANSI (American National Standards Institute), it is the standard language for relational database management systems. SQL statements are used to perform tasks such as update, insert, delete, or retrieve data from a database. Some common relational database management systems that use SQL are: Oracle, Sybase, Microsoft SQL Server, Access, Ingres, etc. Although most database systems use SQL, most of them also have their own additional proprietary extensions that are usually only used on their system. However, the standard SQL commands such as “Select”, “Insert”, “Update”, “Delete”, “Create”, and “Drop” can be used to accomplish almost everything that one needs to do with a database. http://www.sqlcourse.com/intro.html
SQL became a standard of the American National Standards Institute (ANSI) in 1986, and of the International Organization for Standardization (ISO) in 1987.[13] Since then, the standard has been revised to include a larger set of features. Despite the existence of such standards, though, most SQL code is not completely portable among different database systems without adjustments. https://en.wikipedia.org/wiki/SQL
Standards make the product become more portable and easier to understand by other DBAs.
– For instance
- ISO and ANSI dictates that the minimum standard for a query is “Select” and “from.”
- MS t-SQL specifies only one requirement for a query: just one “Select”
What is the most effective use of SQL when working with “Relational Data?” Because SQL is based on the relational database model, SQL provides greater efficiency when working with data (manipulation & management) as sets rather than working with each individual tuples or rows. See – a “Relational Data” Model is based on two mathematical concepts:
- Set theory
- Predicate logic.
Note that it’s not based on individual elements of a set which you might then work with. It views sets of data as “whole” and its mechanics produce better results when your SQL follows this interpretation.
Let’s go further:
– Frist, “Set Theory” is a mathematical theory of sets:
A set is simply a collection of zero or more objects, all of which are different, without any further structure. The following are all sets:
Note that the definition says zero or more: a set with zero members is still a set, even though it is empty. The set with zero elements is written as a pair of empty braces , and is often represented by the symbol .
If two sets have the exact same elements, then they are the same set. There’s nothing special about one set that can distinguish it from others, apart from the elements it contains. The order of the elements isn’t important, so the sets are the same no matter what order we choose to write the elements in:
https://en.wikibooks.org/wiki/Relational_Database_Design/Basic_Concepts
“Sets” connect to each other via “Set operators” and these “connection” can result in meaniful representaitions of the this combined data.
- Union/Union all
- Except/Intersect
– “Relational Data” is also based on “Predicate Logic” which can also be understood as “logical expression.” Some examples of these “Logical expressions” are “teachers making greater than $30,000.” When you apply this to a “relation,” the result can either be true, false, or a missing value (otherwise known as NULL).
The influence of Mathematics in human relationships is still being developed, but I hope we have at least seen that the “Mathematical” principles behind a “Relational Database Model” do speak to the essence of who we are:
- Each of us has a name and attributes that define who we are
- Each of us is unique in this greater set we call “humanity,” and order in this “set” is irrelevant.
These are the characteristics which Edgar Fr. Codd has used to describe a “Relational Data Model.”
Would you say these principles are a reflection of who we are? Is it possible that we could draw meaningful insights from looking at “humanity” through of the key “relations?” The answer is Yes!
 It’s not just data, it is impressions of humanity footprint being digitized and organized into “relational database models” that if understood correctly, it could benefit our future and certainly our commerce.
It’s not just data, it is impressions of humanity footprint being digitized and organized into “relational database models” that if understood correctly, it could benefit our future and certainly our commerce.
I simply want to mention I am just beginner to blogs and honestly liked your website. Very likely I’m likely to bookmark your site . You actually have superb articles and reviews. Thanks for sharing with us your web-site.
I harmonise with your conclusions and will thirstily look forward to your coming updates.
Keep all the articles coming. I love reading through your things. Cheers.
Hi,
I’ve reached out several times but haven’t heard back, which tells me one of three things:
1. You’re interested in giving link back, but haven’t had a chance to get back to me yet.
2. You’re not interested and want me to stop emailing.
3. You’ve fallen and can’t get up – in that case let me know and I’ll call 911.
Can you please reply with 1, 2 or 3? I don’t want to be a bother.
===================== Original Message ===================
Hi,
I am Alex editor at Guru99. There is 69% chance you will not open this email considering its automated cold mail.
But I must highlight I enjoyed your content at http://dataeasy123.com/?p=1
I could not help noticing you linked to http://www.sqlcourse.com/intro.html . I have created a more-in depth article at https://www.guru99.com/mysql-tutorial.html.
Can you link to us? I did be happy to share your page with our 25k Facebook/Twitter/Linkedin Followers as a thank you.
Best,
[Alex]
Thank you for the message Alex. Yes, I’ll be happy to share your link. This is what the website is about..for sure!
And thanks for the option of sharing our page. That would be great!! How would you do it?
Cheers,
Paul